Wordle in 6502 assembly: fun with compression and data structures

After playing around with Commodore BASIC for a while I decided to try my hand at 6502 assembly programming for the Commodore 64. Wordle seemed like a good fit for a first project: while it is not very interesting graphically (especially not when you use the standard character mode set like I ended up doing) it does allow for a few fun programming challenges. I ended up setting the following goals for this game:
- It should use the same word list as the original game, but avoid picking obscure words or profanity as correct answers.
- It should use a fast and compact data structure to check whether the player's guess is in the dictionary.
- To reduce disk or tape loading times, the data structure should initially be compressed.
- The game should support both daily and random words.
I probably ended up reinventing a whole bunch of wheels while coming up with solutions, but for me it's part of the fun to figure these things out by myself.
Getting and filtering the word list
As a starting point I took a list of Wordle words from this GitHub repository, which GitHub user tabatkins indicated were taken from the original game's client-side code. I would use this list for all permissable guesses but still had to filter out obscure words (that would be kind of lame to guess for many people, myself included) and maybe also filter out some profanity for the supposed answers.
To be able to filter out "uncommon" words I used this open frequency data set based on word counts from movie and TV subtitles. I crossed this list with the 5-letter word list and then put them in a table where the words were sorted by frequency. Words that didn't occur in the data set at all I gave frequency 0. I then manually scrolled through this list until I found some cut-off point under which I started seeing multiple words I wasn't familiar with myself. It turns out this occurred around frequency value "150". Because I am not a native English speaker and would probably have a smaller vocabulary than someone who is, this super-subjective threshold will probably do a decent job of reducing the times that players (native speaker or not) will have to guess a word they've never heard of.
Finally, I filtered out profanity by intersecting the word list with this list of offensive words by zacanger manually checking and correcting the result; and then setting the frequency value of all those words to 0 (using these words as guesses is up to the player's discretion). This probably won't guarantee that nobody will ever be offended with any Wordle answers, but this should be a decent effort.
A small and quick data structure
The full ASCII encoded word list is 88 KB, so that won't even fit into the C64's RAM! Therefore, a more memory efficient representation is needed. At the same time, I didn't want there to be any noticeable loading time after the player has entered a guess that is being validated, so lookups to the data structure should be fast.
After playing around with the word list a bit I eventually came up with a data structure consisting of both a "prefix table" which maps each two-letter prefix to the number of words that starts with these two letters, and a "suffix list" that compactly stores the remaining three letters of each word. There are 26 letters in the Latin alphabet, so the number of possible prefixes (and therefore amount of lengths stored in the prefix table) is 26 * 26 = 676.
ABOUT
STRAW
THANK
THING
THINK
ZEBRA
The prefix counts are as follows:
AA: 0
AB: 1
AC: 0
<lots of zeroes>
ST: 1
<lots of zeroes>
TH: 3
<lots of zeroes>
ZE: 1
<lots of zeroes>
ZZ: 0
And the suffixes would be basically stored like this:
OUT
RAW
ANK
ING
INK
BRA
As you can imagine, this'll already save a lot of space for big word lists, because you no longer have to actually store the first two letters of each word; just the 676 entries of the prefix table.
You can test whether a guess is valid by summing up all prior prefixes and using that as a starting index in the suffix list. For example, if the player would guess "THROW", this process would go as follows:
- T is letter 19 in the alphabet (when counting A as 0) and H is letter 7. 19 * 26 + 7 = 501
- If element 501 of the prefix table were equal to 0, we could quit immediately and say the guess is invalid. This is not the case, however.
- Scan through the prefix table until element 501 is reached, adding all scanned bytes to a counter. The counter value will be 1 + 1 + 498 * 0 = 2.
- The counter value now represents the offset in the suffix table, which starts at "ANK". The value at element 501 is 3, so that means that we should check 3 suffixes from here ("ANK", "ING" and "INK").
- Match these suffixes with the suffix of the guess ("ROW"). Since none match, report that the guess is invalid.
The worst-case complexity of this algorithm is O(size of prefix table + maximal prefix count value). Since the table size is 676 and the maximal value was less than 300, this is pretty manageable. It may not beat a binary search in efficiency but is easily fast enough to be instantaneous.
So how do we actually store the suffixes? There are 26 letters, which can be encoded within 5 bits. So if we pack three letters together we get 15 bits. If we put that in a two-byte word that leaves one bit left, that we can conveniently use to indicate whether a word has been filtered out the answer list or not.
What about the word counts stored in the prefix table? It turns out almost all prefixes occur less than 256 times, meaning the count would fit in a single byte. One annoying exception is the prefix "MA", which appears 271 times. I worked around this by applying a small permutation to each word before compressing or checking it: if a word starts with "MAC", then change it into "MCA" or vice-versa. This small change was enough to make all prefix counts fit in a byte. Of course this approach wouldn't work anymore if I would ever port this to another language, and then I'd probably have to code different permutations like this one.
So now the in-RAM data structure takes 676 bytes to encode the prefixes, and a further two bytes per word. The size of the word list is 14,855 so the necessary RAM capacity is around 30.4 KB, less than half of what the C64's got available!
Doing some compression
Since the data structure fits in RAM in its entirety, it's not technically necessary to do any compression. However, if I could reduce the stored size of this list it would improve load times if you'd load the game from a floppy disk (and especially when loading from tape!). Sure, most people would just be using emulators or flash cards nowadays, but it's still fun to do some optimizing here.
You can go pretty far designing a custom compression scheme that tries to squeeze out every single bit of redundancy, but the fancier the scheme the more complex the decompression implementation. This might make decompression slow and kind of defeat the purpose of reducing load times. Also, because I'm a novice 6052 programmer I would probably make lots of mistakes and would have to spent a lot of extra time on debugging.
After some experimentation I came up with a pretty simple variable-length diff encoding mechanism that was very simple to decompress while still performing better than general-purpose DEFLATE compression on the data structure. Basically I would sort the suffices for each prefix and store the differences between them. If the difference would fit in 7 bits (i.e. is smaller than 128) I would encode it as a single byte with the most significant byte set to zero. Otherwise, I would set the first bit to 1 and use the remaining 15 bits to represent the difference. In cases where two suffixes were too far apart I would reorder the list a bit and take advantage of overflow to make sure every diff would fit in 15 bits.
When applying this compression scheme the word table is further reduced from 30.4 KB to 22.6 KB. Not a massive reduction but still pretty neat. Decompression by the CPU does add a few seconds of extra load time but it does look like an improvement over the time it would take to load those additional 8 kilobytes from disk.
Because both the compressed and uncompressed tables fit in RAM together (as long as I switch all banks to RAM whenever interacting with them) there was no need to put the compressed word table in a separate file and read that incrementally. Instead, I could just pack the compressed table into RAM and store the decompressed output in the remaining available RAM.
Daily and random words
When the player chooses to go for a random word, I used a pretty standard Xorshift LFSR seeded with the jiffy timer at the button is pressed.
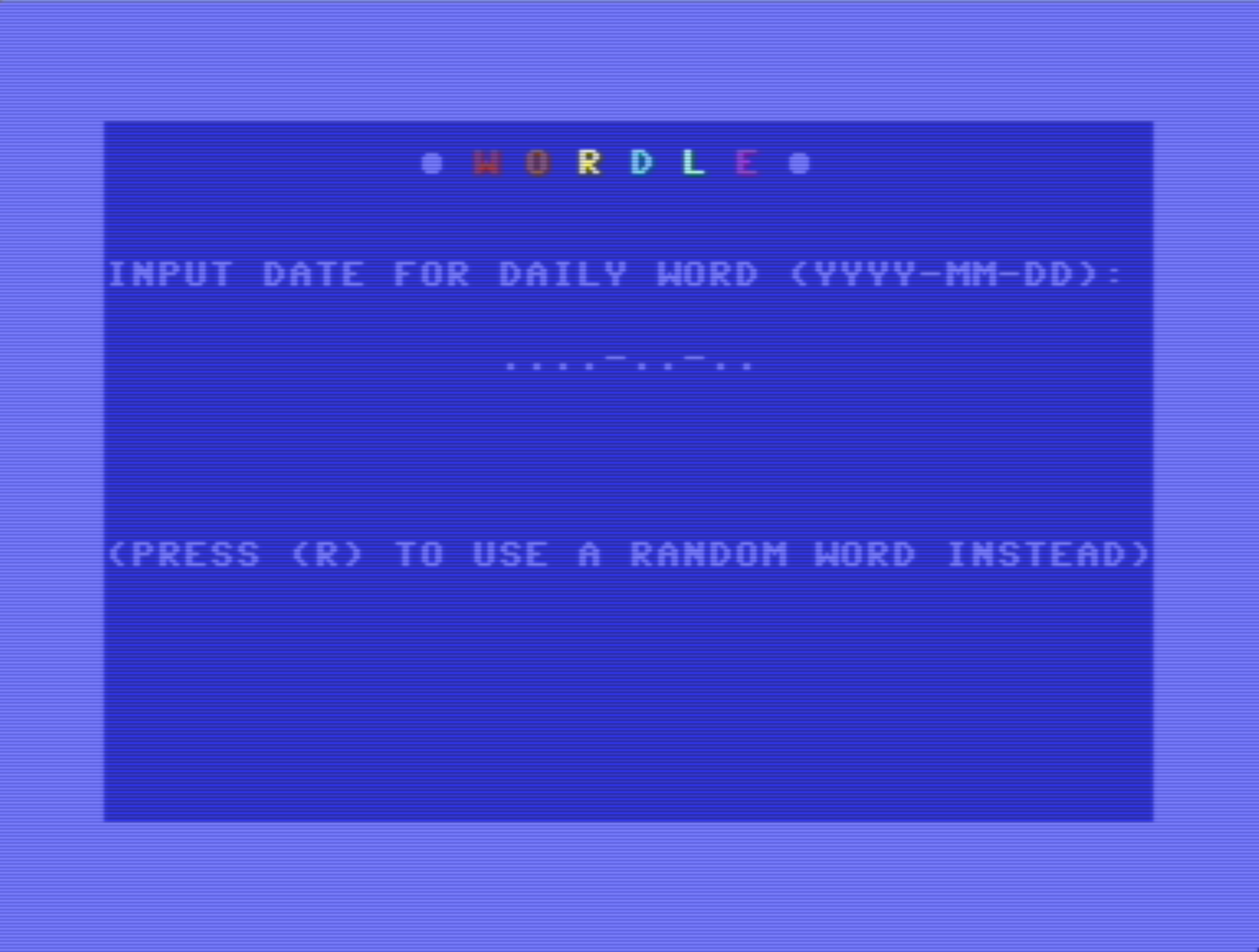
Alternatively, the player can also go for a 'daily wordle'. Because the C64 does not have a persistent clock, the player just has to enter the date themselves. Then this date is used to dervive an RNG seed, instead of the timer. You can enter in any valid date between the years 1 and 9999 CE, so you can also just plug in birthdays or dates of special events, to compete with friends.
Files
Get Wordle for Commodore 64
Wordle for Commodore 64
| Status | Released |
| Author | Aardvark Soup |
| Genre | Puzzle |
| Tags | Commodore 64, Word game, Wordle |
Leave a comment
Log in with itch.io to leave a comment.